Introduction
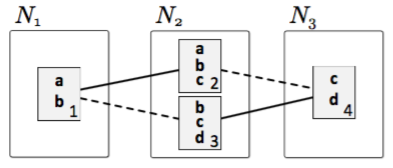
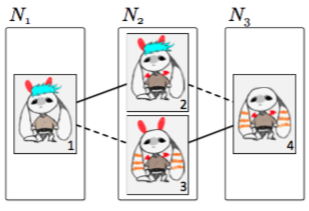
Figure 1: Sample inputs $N_{1}, N_{2}$ and $N_{3}$
N-way matching consists of finding correspondences between elements of multiple inputs. It is useful in many software engineering practices like merging branches of a software configuration management system. [3] Creating an n-way match boils down to identifying groups of elements from distinct inputs that are similar to each other, i.e., that share properties [6].
Figure 1 shows an example of matching elements from inputs $N_1$, $N_2$, and $N_3$. The dotted and solid lines represent two different matching options. Paired elements share more properties in the match represented by the solid lines than those in the match represented by the dotted lines. Finding an optimal n-way match is straightforward for simple examples, yet finding an optimal match for larger cases has been shown to be NP-hard; that is, there is no algorithm that produces the optimal solution in polynomial time. This makes n-way matching infeasible to automate [6].
Thus far, it has been the approach to develop heuristic algorithms that approximate the optimal solution in polynomial time [6]. This paper explores an alternative direction for establishing n-way matches. Our approach is inspired by the idea of games with a purpose, which crowd-source a solution to a computationally expensive problem by encoding it into a game for people to play [8].

Figure 2: Main screen for the Matchmakers game.
Approach
Our game, MatchMakers, uses people’s abilities to perform visual comparisons in a fast and efficient manner [4, 7]. We encode elements of inputs as aliens.
For example, Figure 2 shows aliens that represent elements in Figure 1. Input elements that share more properties are more visually similar. The goal of the player is to help the aliens form “groups of friends”, i.e., to create groups of visually similar aliens.
The game starts from the best solution so far – either the solution produced by the best heuristic algorithm, or by a previous player that has improved that solution. A player begins by being presented an alien for whom they must form a group. The rest of the aliens are displayed below, each within its own group. Aliens that are similar to the ones in the group being formed are highlighted, making for less overwhelming in-game decisions. If a player manages to form a group of aliens which causes the score of the solution to increase, then that solution is saved, and the player restarts the game with a new alien. An example of the game layout is shown in Figure 2.
In order for people to have the greatest chance at improving the score, we aim to provide good game support. We want to implement an effective highlighting strategy, i.e., a strategy that is general enough so that players are not missing good aliens to add their group, but also specific enough so that the game is not overwhelming. We also want to figure out how to best pick the alien from which players start forming a group. If players are presented with aliens that are difficult to group, they might become exhausted and stop playing the game.
In order to speed up the evaluation of the different game configurations, as well as identify whether it is feasible for players to improve the solutions formed by the best heuristic algorithm, we first built an automated algorithm that simulates a human player. This algorithm is referred to as HSim. Based on the configuration that results in the best scores over a large number of real world case studies, we set the design of the game and approximated the success that players might expect to achieve.
Analysis
We tested HSimwith four different configuration parameters: highlighting, ordering, reshuffling, and selecting. Highlighting is as described in Section 2. Ordering defines the order in which aliens are presented for grouping. Reshuffling defines whether we reorder the aliens for grouping every time a player manages to improve the score. Selecting assigns a strategy for choosing which aliens to append to the current group. This is the only configuration parameter which does not have an influence on game design, but affects HSim’s ability to improve the heuristic scores. The conceptual design of the human simulator is shown in Algorithm 1.
We used 4 highlighting strategies, 7 ordering strategies, 3 reshuffling strategies, and 2 selecting strategies, for a total of 168 different variants of HSim. As case studies, we used 15 examples taken from existing work on n-way matching [6, 5, 2].
The best configuration of HSimresults in an average improvement of 9.3% over the solutions of the best heuristic algorithm. To test whether this is a significant improvement, we performed a paired t-test using PROC TTEST in SAS [1]. We ran this test because our data consisted of paired observations for the two algorithms over the 15 different cases. The null hypothesis for the t-test was that the two data sets for the different algorithms came from the same underlying distribution. The t-test returned a p-value of 0.0019, which is less than 0.05, rejecting the null hypothesis and signifying that HSim was able to make a significant improvement over the solutions found by the best heuristic algorithm.

Figure 3: Algorithm 1: Conceptual steps of HSim.
Conclusion
In this paper, we reported on our experience designing MatchMakers– a game for solving the n-way match problem. We identified a number of strategies regarding how the game could support human players in making better choices and experimented with an automated simulator to help select the most effective ones for the game. Furthermore, we have proven that, given a fairly simple strategy for choosing elements to append to a given group, an automated version of a human player is able to significantly improve the scores achieved by the best heuristic algorithm [6].
In the future, we would like to conduct a study with real human players to assess whether they are also able to significantly improve the solutions achieved by the best heuristic algorithms for n-way matching, as well as how they compare to our naive implementation of a human player. We also hope to redesign the human simulator to employ more intelligent strategies for finding an n-way match in hopes of improving its performance.
Acknowledgments
We thank Christina Chung, Asako Matsuoka, Yueti Yang, Si Hua Cao Liu, Lionheart Xiong, and Angel You for developing the game and Nicole Sultanam on her guidance on usability-related issues. We also thank the very gifted Fei Huang for drawing the game images.
References
-
SAS Analytics Software
-
Sven Apel, Christian K ̈astner, and Christian Lengauer. Language-Independent and AutomatedSoftware Composition: The FeatureHouse Experience.IEEE Transactions of Software Engineer-ing, 39(1):63–79, 2013
-
Udo Kelter, J ̈urgen Wehren, and J ̈org Niere. A Generic Difference Algorithm for UML Models.InSoftware Engineering 2005, Fachtagung des GI-Fachbereichs Softwaretechnik, 8.-11.3.2005 in Essen, pages 105–116, 2005.
-
Hemank Lamba, Ankit Sarkar, Mayank Vatsa, Richa Singh, and Afzel Noore. Face Recognitionfor Look-Alikes: A Preliminary Study. In Proc. of the IEEE International Joint Conference on Biometrics (IJCB’11), pages 1–6, 2011.
-
Lukas Linsbauer, Roberto Erick Lopez-Herrejon, and Alexander Egyed. Recovering Traceability between Features and Code in Product Variants. In Proc. of the International Software Product Line Conference (SPLC’13), pages 131–140, 2013.
-
Julia Rubin and Marsha Chechik. N-Way Model Merging. In Proc. ESEC/FSE, pages 301–311,2013.
-
Pawan Sinha, Benjamin Balas, Yuri Ostrovsky, and Richard Russell. Face Recognition byHumans: Nineteen Results All Computer Vision Researchers Should Know About. Proc. of the IEEE, 94(11):1948–1962, 2006.
-
Luis von Ahn. Games with a Purpose. IEEE Computer, 39(6):92–94, 2006.